对OpenAI官网的Sora的技术报告的解读。
Intro
- 集中两点:
- 把多种类型的视觉数据转化为统一表示的方法。
- Sora 的能力和限制 的 定性评估。
- 能力:生成多种时长、宽纵比、清晰度的视频,最长可生成1分钟的高保真视频。
- Sora证明随着视频生成模型越大,对物理和数字世界的模拟越好
把视频数据打成patches
- 受到LLM在多种文本数据(代码、数学和多种自然语言)上训练的启发,作者在想办法 怎么 继承这样的优点:
- 之前已证明:patches 已经展示了对视觉数据是有效的表征。
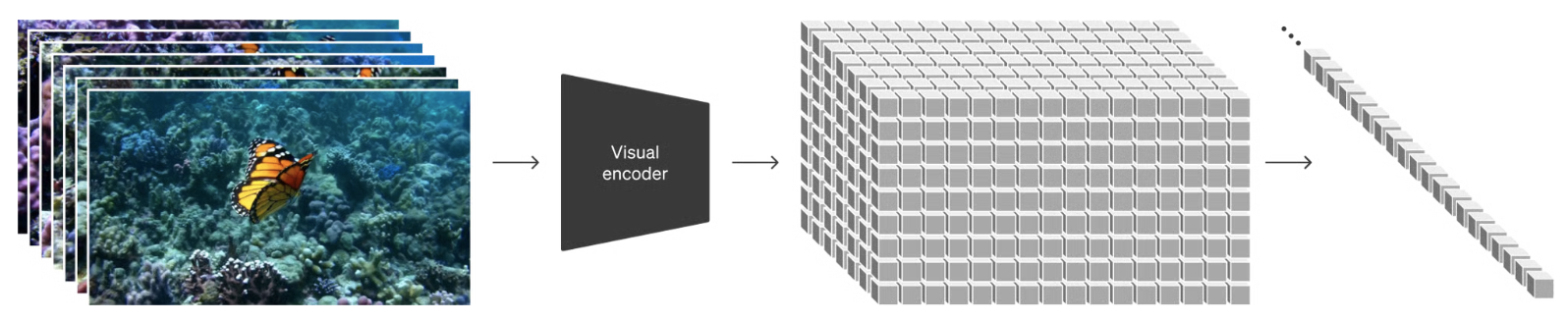
- 之前已证明:patches 已经展示了对视觉数据是有效的表征。
视频压缩网络
- 如上图,网络输入的是原始视频,输出的是潜在的表征,这个压缩是空间和时间上的。
- Sora 是在这个潜在表征上 训练和推理时生成视频的。
- 作者也训练了一个响应的解码器模型,把生成的潜在表征映射回像素空间。
时空潜在patches(Spacetime latent patches)
- 作者把一个序列的时空patches作为transformer的tokens。
- 这个机制也可以用在图片上,因为图片就是单帧的视频。
- 这种基于patches的表征,使Sora能够在不同分辨率、时长、长宽比的视频和图片上进行训练。
- 在推理时,能通过排列的合适尺寸的随机初始化patches,我们可以控制生产视频的尺寸。
视频生成的scaling transformers
- Sora 是一个diffusion model. 也是一个diffusion transformer.
- 输入 noisy的patches(和如文本prompts一样的conditioning information),它被训练预测一个clean的patches.
- Transformers已经被证明,通过规模增大,效果会显著增加,如language modeling, computer vision, image generation.
- 这篇工作也随着规模增大,而效果变好。
可变的 时长、清晰度、长宽比
- 过去对图像和视频生成的方法会进行resize, crop, ✂️ videos到一个标准尺寸(4秒的$256 \times 256$ 的视频)。
- 然而作者发现在原始数据上训练有一些好处:
- 灵活采样:
- 可生成1920x1080p ,1080x1920p及其间的任何尺寸。
- 可以直接生成完美适配任何屏幕的视频。
- 还可以快速获得要生成视频的预览版。
- 改进了取景和构图
- 灵活采样:
自然语言理解
- 如何生成text-video的大量训练集:
- 把DALL·E 3中的重新生成字幕技术引入到视频中。
- 首先训练一个描述非常丰富的字幕生成模型。通过这种方式,可提升prompt的保真度和整体视频质量。
- 也用了GPT使prompt变得更长、细节更丰富。
主要任务
- 完美循环视频
- 把图片变视频
- 向前、向后扩展视频
- 根据prompt编辑视频。
- 融合来那个完全不同的视频成为新视频。
- 生成图像。
- 新兴的模拟能力:
- 3D 连贯性:可产生动态相机运动拍摄出来的视频。
- 长范围的 关联性 和 物体特征不变形:
- 即使被遮挡或离开画面,也能保持物体的不变形(often, though not always)
- 能对同一对象产生不同的镜头。
- 模拟真实的和物理世界的交互。
- 模拟数码世界。
缺陷:
- 不能准确模拟现实世界。
- 再交互中,不总是能产生物体状态的正确改变。
- 长的视频中出现的不连贯性。