The detail of TriDet.
Intro
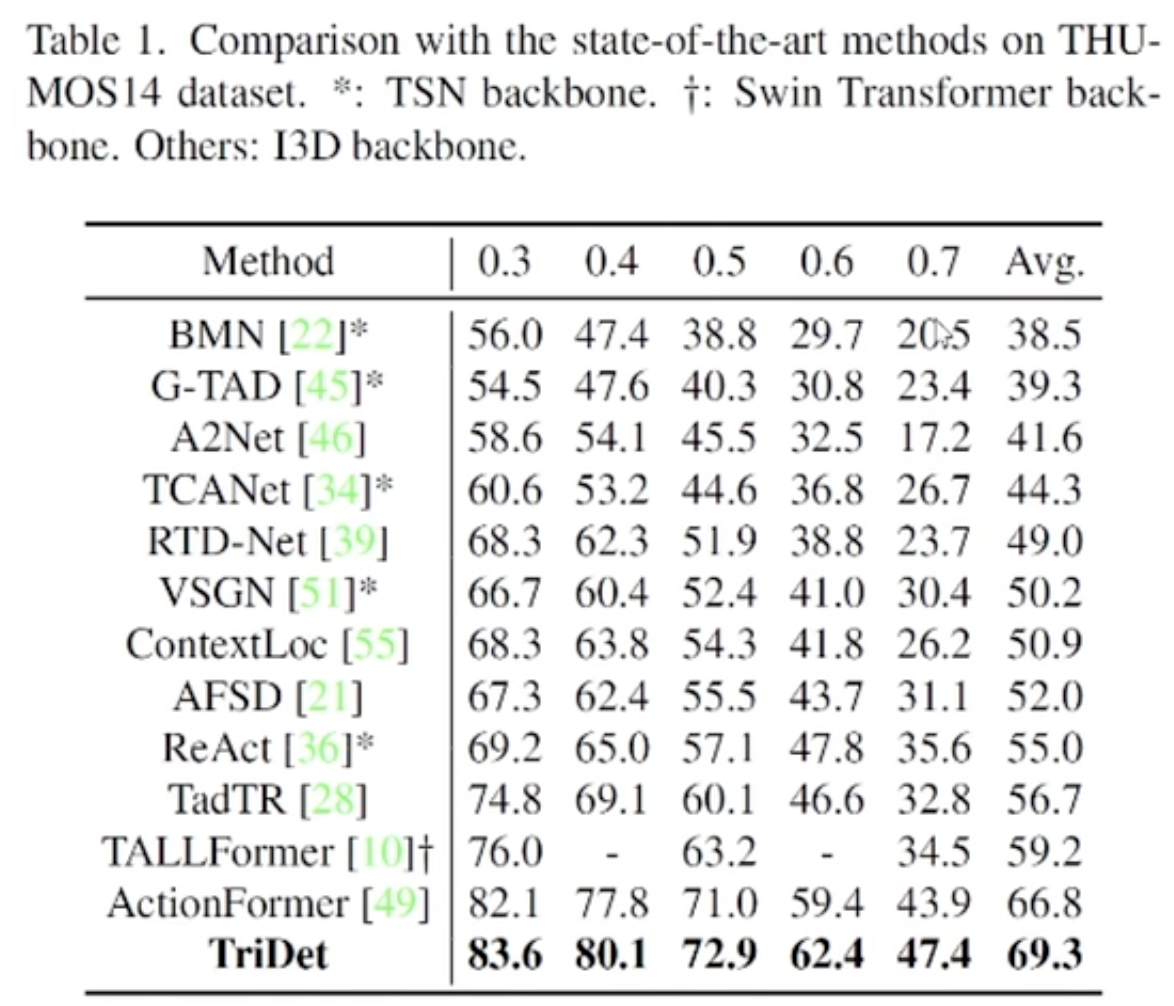
- TriDet: Temporal Action Detection with Relative Boundary Modeling.
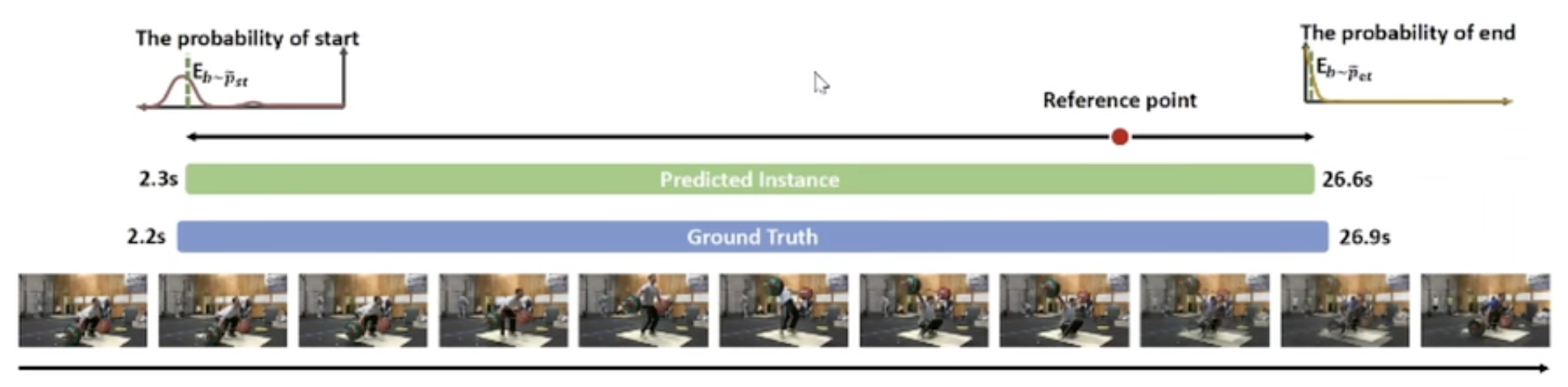
Temporal Action Detection(TAD)
- Detect all action boundaries and categories from an untrimmed video.

- The pipeline of TAD:
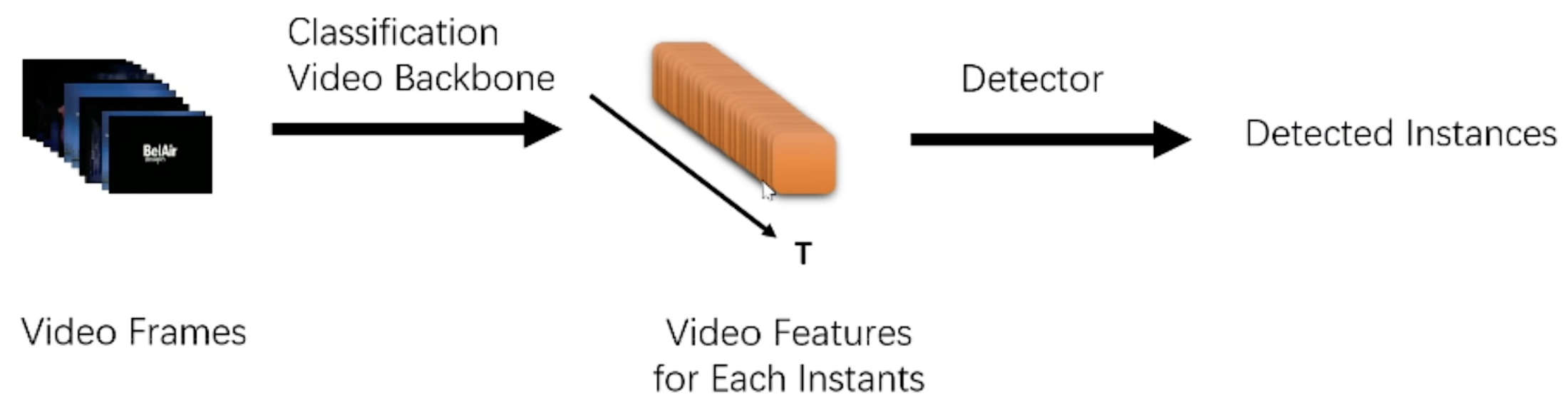
- backbone:
- use the pre-trained model in Action Recognition Task.
- to get the feature map of each frame.
- backbone:
- Detect all action boundaries and categories from an untrimmed video.
The core Focus of the author:
- get more accuracy boundary.
- explore Transformer for TAD.
Related Work
Intro
- two classes by the method of boundary dividing for TAD works using Transformer:
Segment-level prediction
- based on extracted feature maps, get a clip, and simple, global expression(e.g., pooling), finally judge whether the clip is the target.
- e.g. both of the below are two-stage network(like Faster-Rcnn, one stage generate lots of proposals, the second stage regresses and classifies proposals):
- BMN
- PGCN:
- use GCN to refine every proposal.
- The method can’t be trained end-to-end.
- End-to-end:
- TadTR
- ReAct
Instance-level prediction
Anchor-free Detection
AFSD
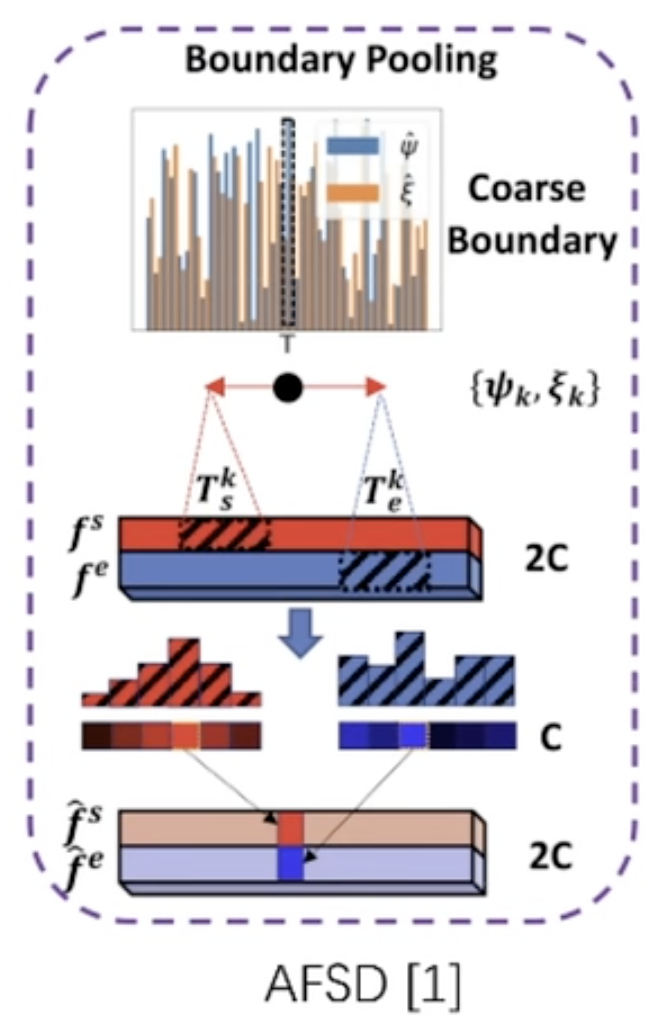
- predict the distance to the start or end boundary.
- then make the position pointed by most other position as the boundary.
ActionFormer
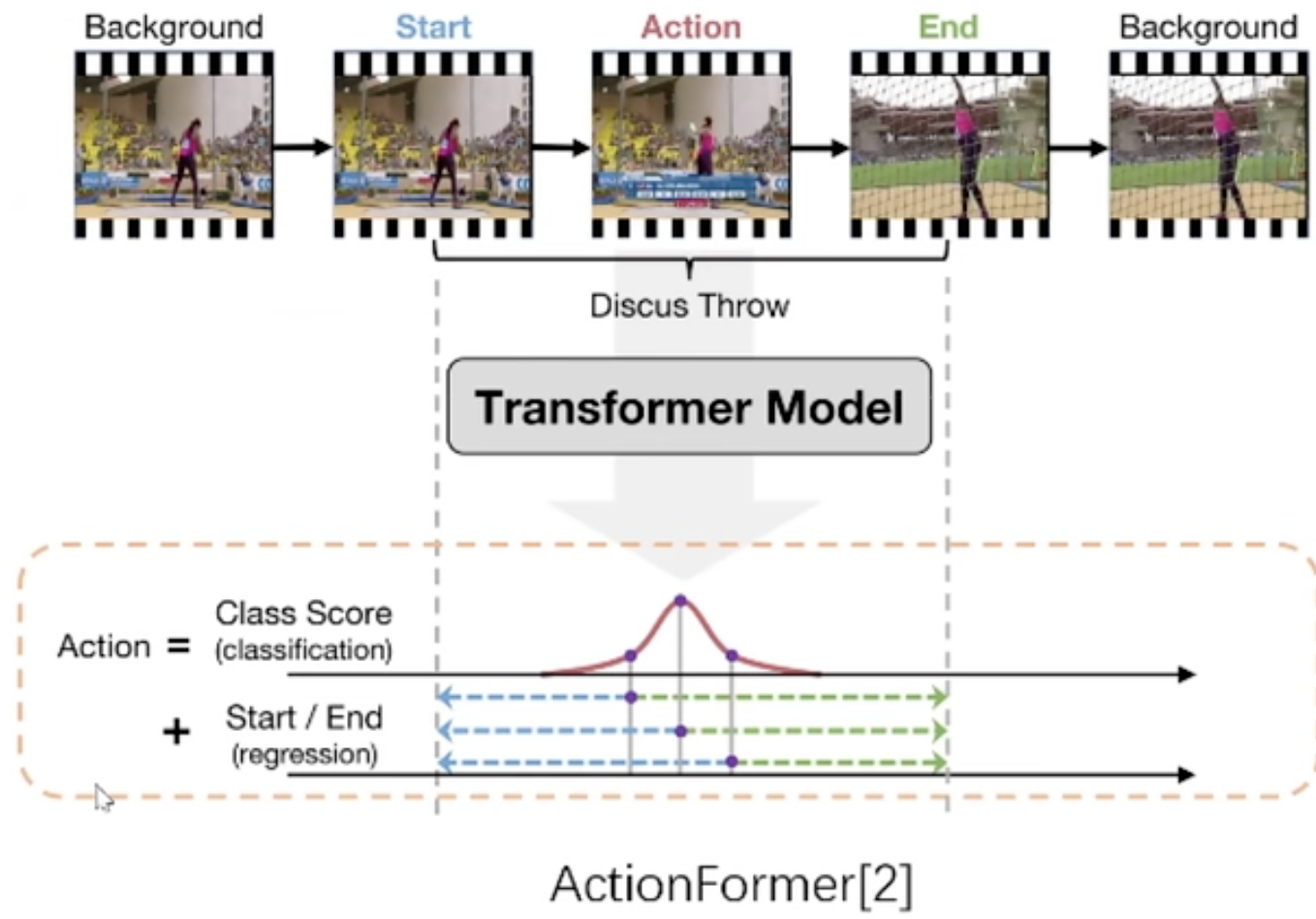
- Using slide-window to apply self-attention.
- In 2022, the work in TAD improved obviously.
- So TriDet carry out based on the work.
Segmentation
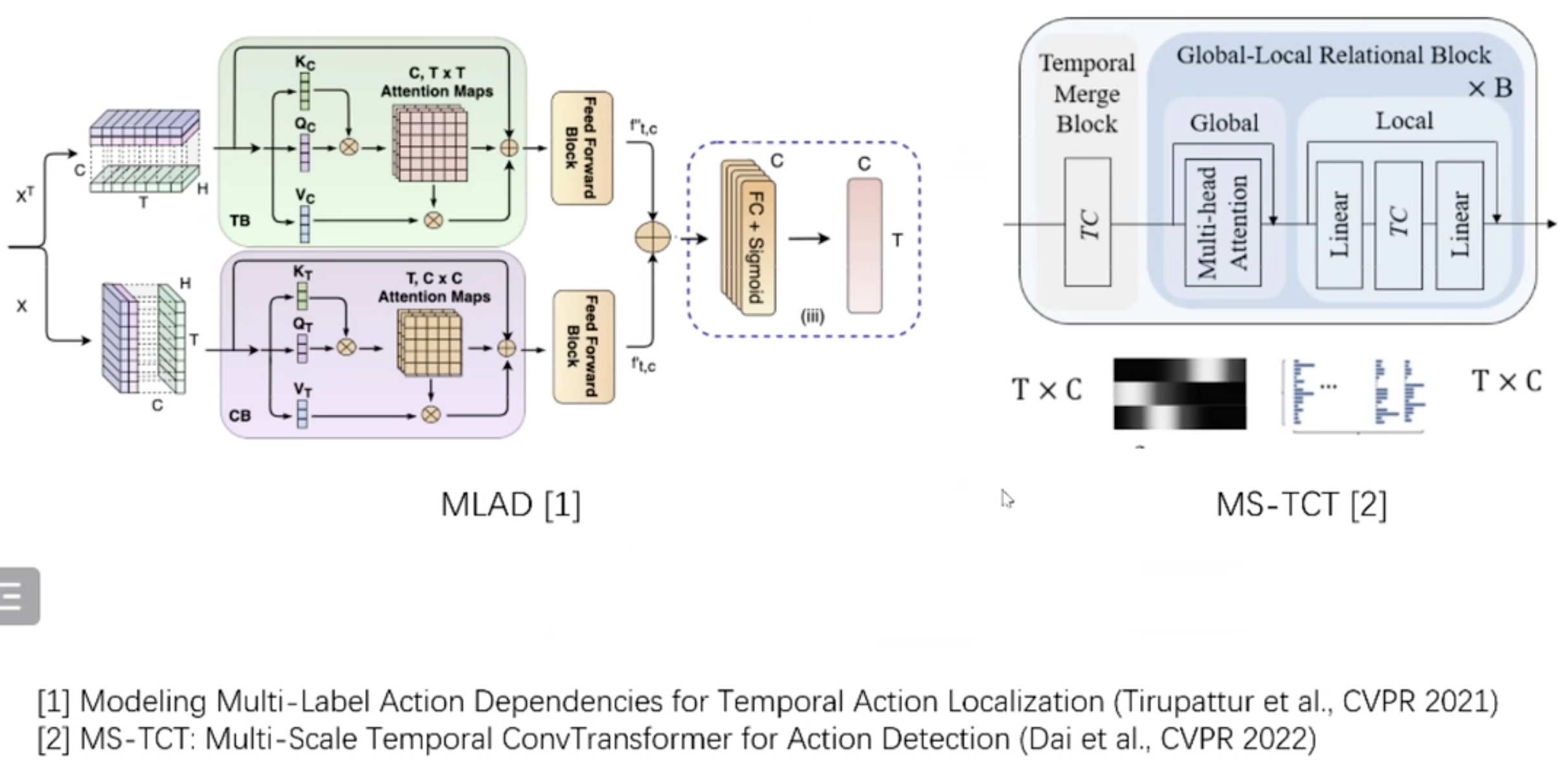
MLAD
- Apply self-attention in the time level dimension and the classes level dimension.
- Add the two attentions of the two level dimensions to build the final feature map.
MS-TCT
- Add a CNN module after a traditional self-attention module.
- Add residual connections.
Summary
- For the above two works, they both pay attention to modifying the self-attention.
- So, it indicates that the original self-attention cannot be applied to TAD.
Pros and Cons
Segment-level prediction
- Contain global representation of segments.
- Larger receptive field.
- More information.
- Detailed Information at each instant is discarded.
- Highly depend on the accuracy of segments.

Instant-level prediction
- Contain detailed representation of instants.
- Smaller receptive field.
- The requirement for feature distinguishability is high. (use the strong backbone to extract features.)
- The degree of response varies greatly with different videos.
Motivation of Trident-head
- Consider both instant-level and segment-level feature.
- Set it as the segment-level feature that the predicted frame with the fixed number of adjacent frames.
- Set the segment-level feature as instant-level feature?
Trident-head
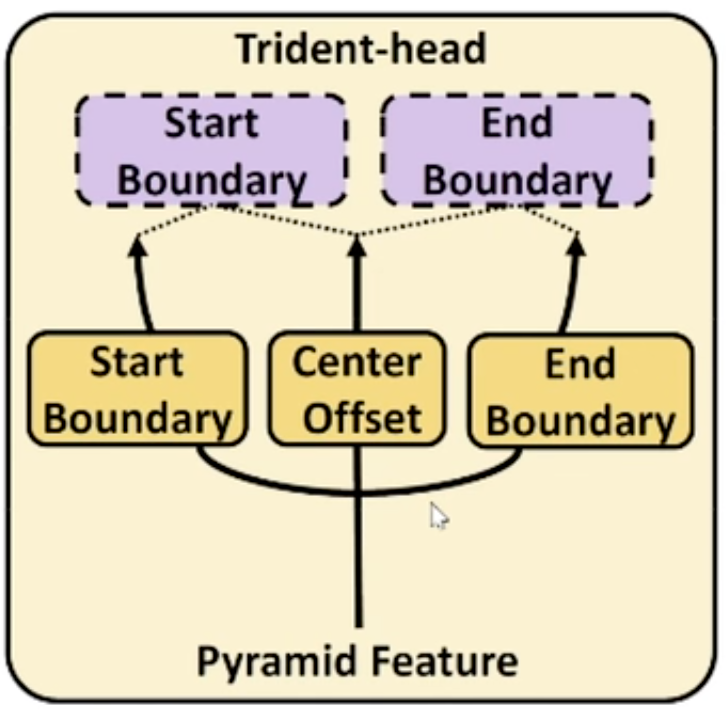
- Three branch:
- Start Boundary and End Boundary would extract the segment-level feature.
- Center Offset would extract instance-level feature.
- E.G., Predicted Start Boundary is decided by Start Boundary and Center Offset:
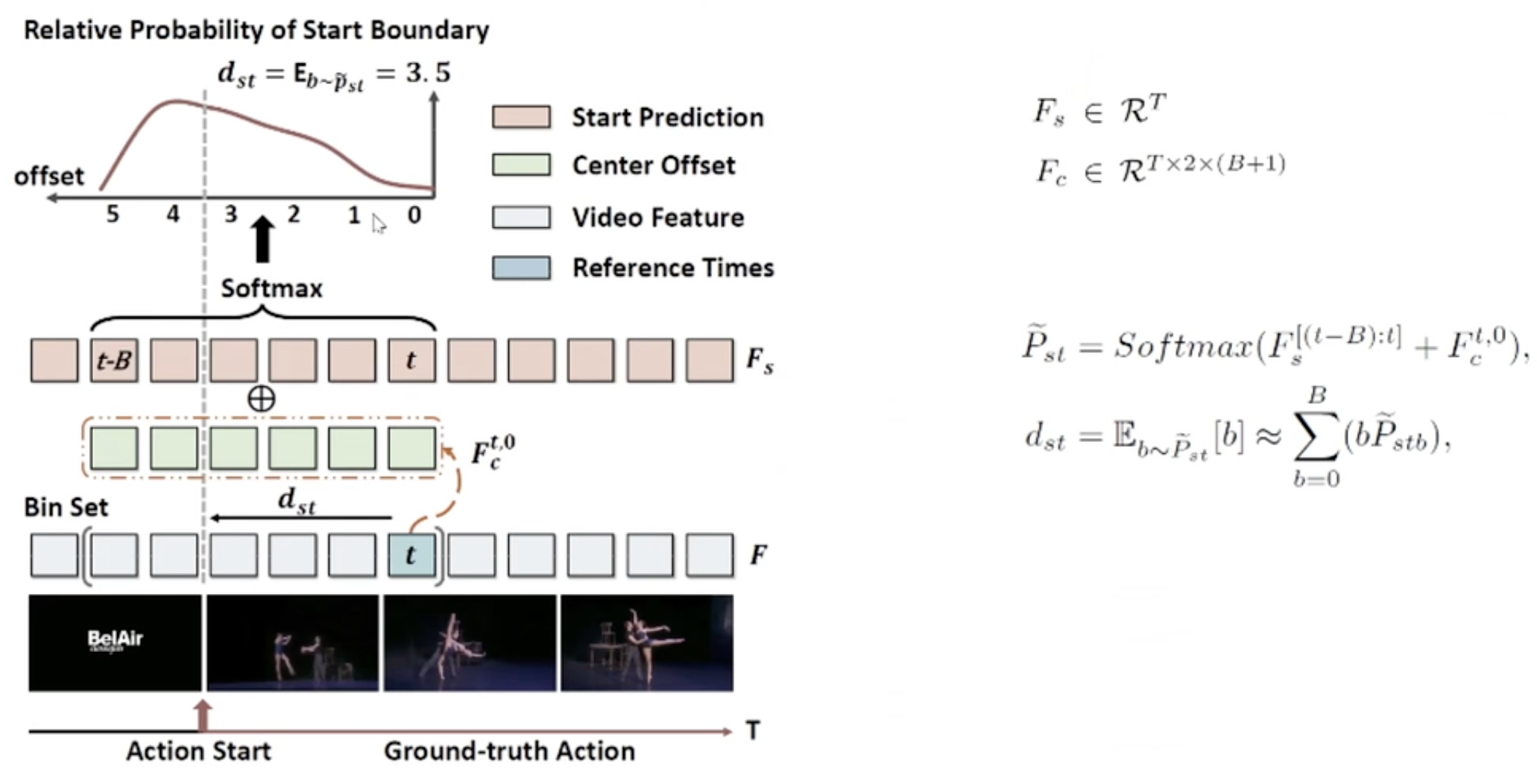
- Expectation is decided by B:
- if B is too small, we can’t find the more far boundary.
- if B is too big, the difficulty of learning and convergence of training is more great, so that the predicted result is not accuracy.
- Combined with FPN:
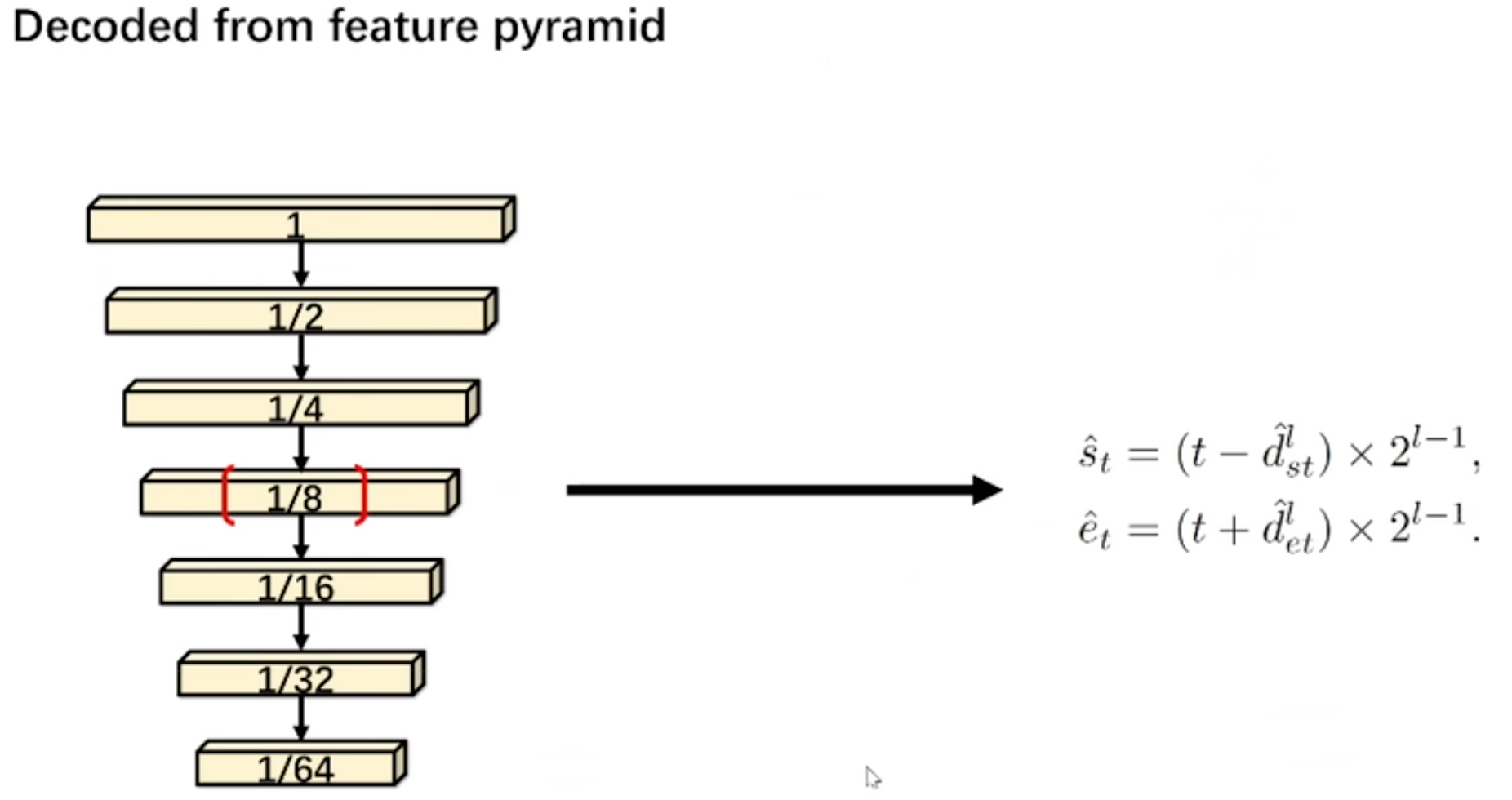
- In the different level layers, the fixed number of B is set to product different Bs, so it can have small and big Bs simultaneously.
- While finally outputting, the predicted results in different layers times corresponding scale ratio to get real position.
The second question: Attention in Temporal Dimension.
- Many methods require complex attention mechanisms to make the network work.
- The success of the previous transformer-based layers(in TAD) primarily relies on their macro-architecture, rather than the self-attention mechanism.
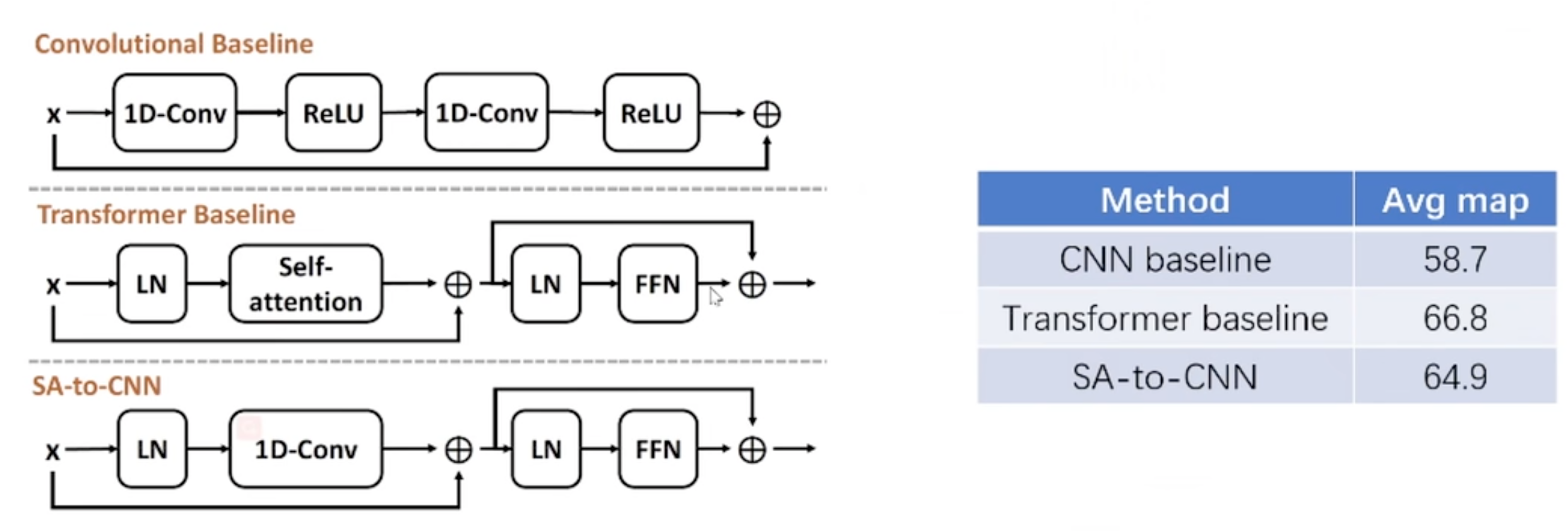
- Above, when 1D-Conv take the place of Self-attention, the Avg map only drops by 1.9, but when CNN baseline takes the place of Transformer baseline, the Avg map drops very much, which indicates that Transformer is effective depending to its structure not Self-attention.
The Rank Loss Problem of Self Attention

In TAD, making the features same is disastrous, because we need to distinguish a position is the action or not.
Pure LayerNorm will normalize the features $x\in R^n$ to a modulus $\sqrt{n}$ :
$x’ = LayerNorm(x)$$x’_i = \frac{x_i-mean(x)}{\frac{1}{n} {\textstyle \sum_{n}^{}(x_i-mean(x))^2}}$
$\left | x’ \right | ^2_2 = {\textstyle \sum_{n}^{}x’^2_i}=n$
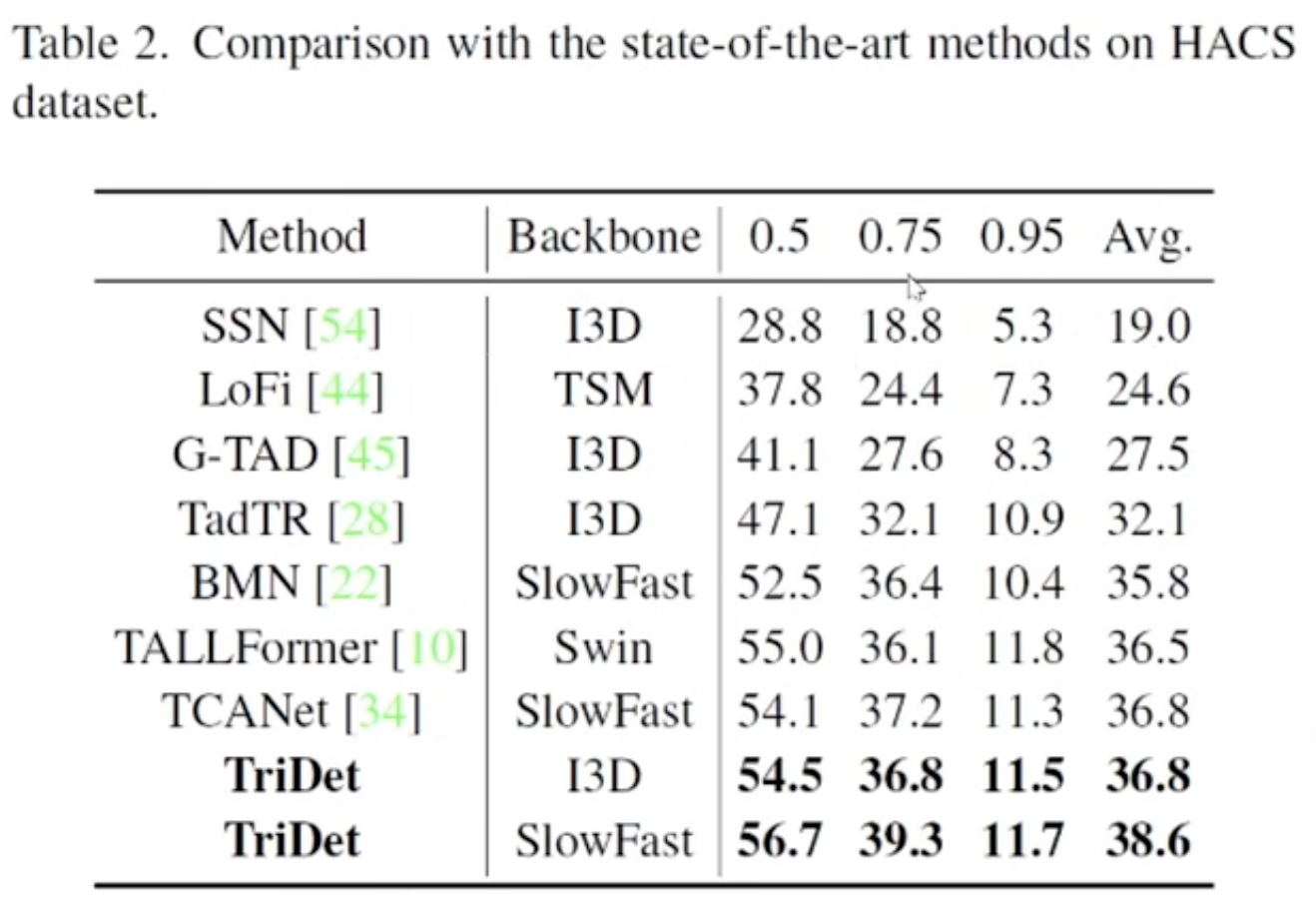
The Evidence on HACS:
we consider the cosine similarity:
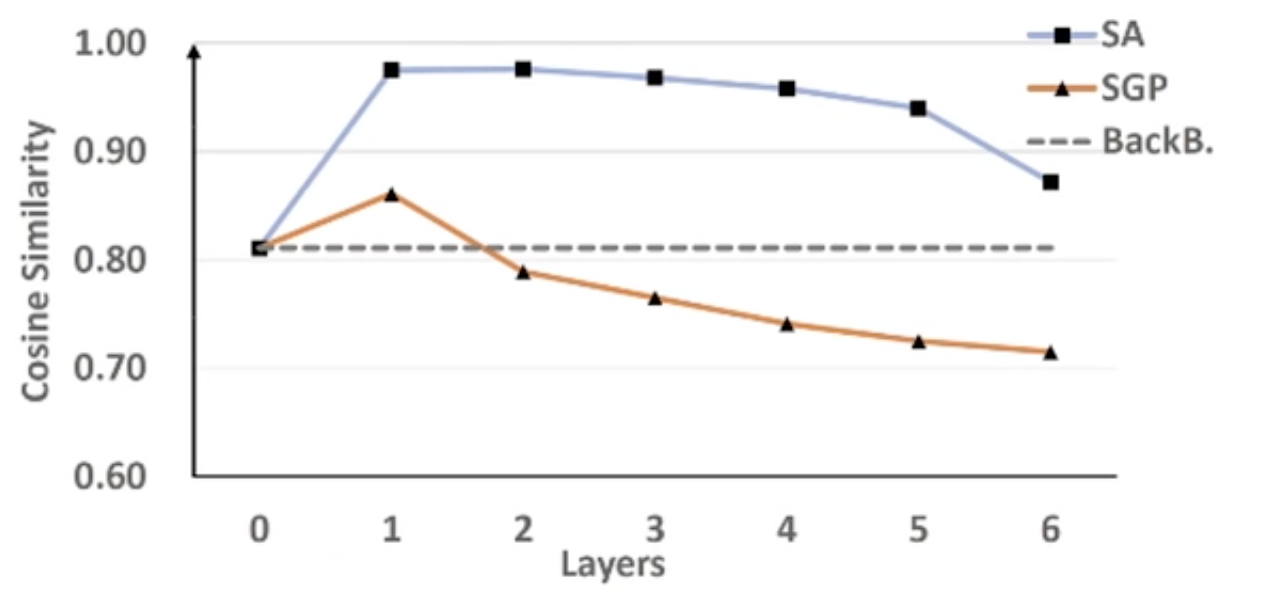
- here SA is Self-Attention, SGP is proposed by the author, BackB is the backbone network to extract the feature.
- here the value is the average of the cosine similarity of every feature and average feature in the same layer ?
- Consider the Self Attention:
$V’=WV$
$W=Softmax(\frac{QK^T}{\sqrt{d}})$
W is non-negative and the sum of each row is 1, thus the $V’$ are [[conceptAI#convex combination|convex combination]] for the input $V$.
But the value in Convolution kernel can be negative, and the sum can be not 1.
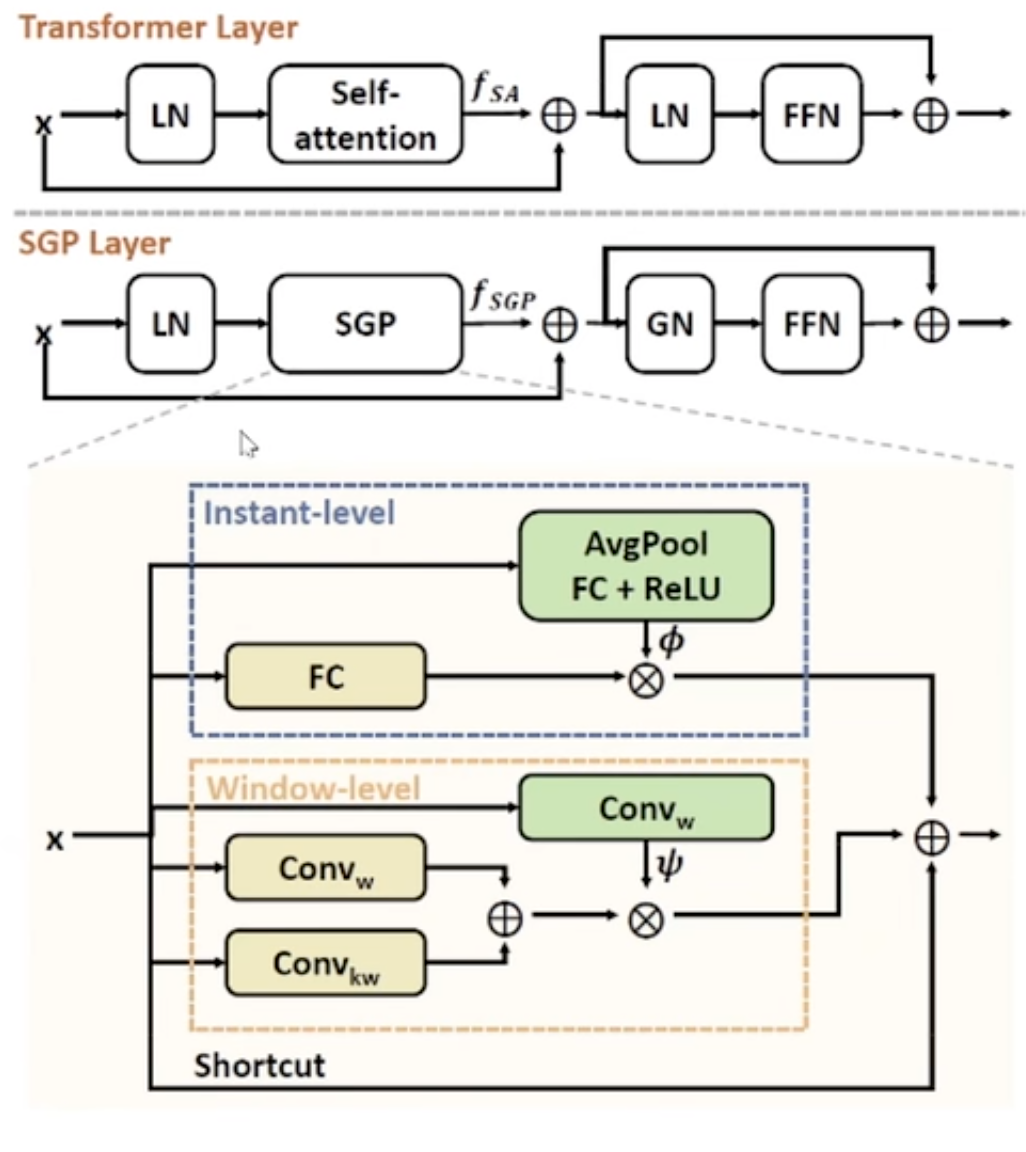
The author’s Solution: The SGP layer
- increase the discrimination of feature.
capture temporal information with different scales of receptive fields.
$f_{SGP}=\Phi (x)FC(x)+\psi(x)(Conv_w(x)+Conv_{kw}(x))+x$,$\Phi(x)=ReLU(FC(AvgPool(x)))$,
$\psi(x)=Conv_w(x)$
Window-level: make the network extract features in different scales adaptively.
In detail:
- the author uses the depth-wise convolution to reduce the computation of the network.
- add a additional residual connection.
Experiment
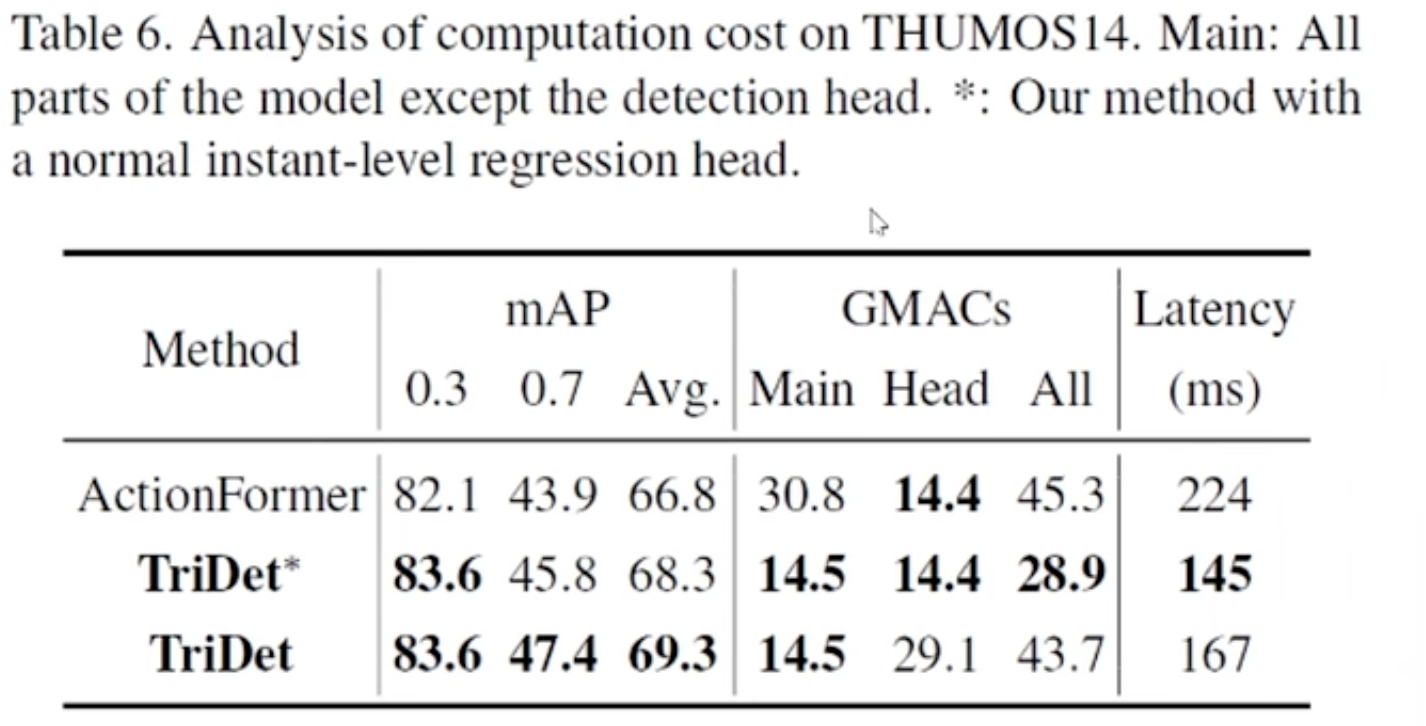
The performance is so good: the accuracy is higher, the speed is faster.